Clickhouse’s MergeTree Engine Storage Structure
Overview
A data table is divided into several data parts, each corresponding to a directory in the file system. The following SQL can be used to query information about the data parts.
SELECT table, name, path, active, * FROM `system`.parts WHERE table = '<table name>'
A <data part> is a directory, and its file structure is as follows:
- **<data part 1>**
○ checksums.txt
○ columns.txt
○ **\<column\>.bin**
○ **\<column\>.mrk**
○ count.txt
○ **primary.idx**
○ [partition.dat]
○ **[minmax_\<column\>.idx]**
○ **[skp_idx_\<column\>.idx]**
○ [skp_idx_<column>.mrk]
- <data part 2>
○ …
○ …
- <data part 3>
○ …
○ …
Part Directory
Data exists in the Part directory. A batch Insert operation will produce a Part. Multiple Parts belong to a single Partition, and Parts of a Partition will be merged in the background. The naming of the Parts directory can reflect its Partition and the range of record IDs:
<Partition ID>_<Min ID>_<Max ID>_<Level>
Partition ID is the key of the partition, which can be a column or multiple columns.
Min ID, Max ID represent the minimum ID and maximum ID of the data in this Part, constructing a range. Level is the concept of hierarchy, which is self-increasing, and can be understood as each update operation is equivalent to adding a “layer”.
Parts will be merged in the background according to Partition, which is very important.
Reference code: src\Storages\MergeTree\MergeTreeData.h
[column].bin | data.bin
Stores the actual data of a column’s file. When using the wide part mode, such a file is generated for each column, and the file name is the name of the column.
Another mode is the compact part mode, in which all columns’ data is placed in a single file data.bin.
When the original size of the data before compression exceeds the threshold min_bytes_for_wide_part, or the number of data rows exceeds the threshold min_rows_for_wide_part, the wide part mode will be used; otherwise, the compact part mode is used.
The data in the .bin file is stored in blocks, which may be compressed or uncompressed. This is determined by the Clickhouse parameters max_compress_block_size and min_compress_block_size. If compression is decided, the default lz4 compression format is used.
A block is divided into two parts:
- Header
The header occupies 9 bytes, which are:
- [0] Encoder, such as lz4
- [1-4] The size of the entire block after compression
- [5-8] The size of the entire block before compression
- [9-24] Checksum
- Data
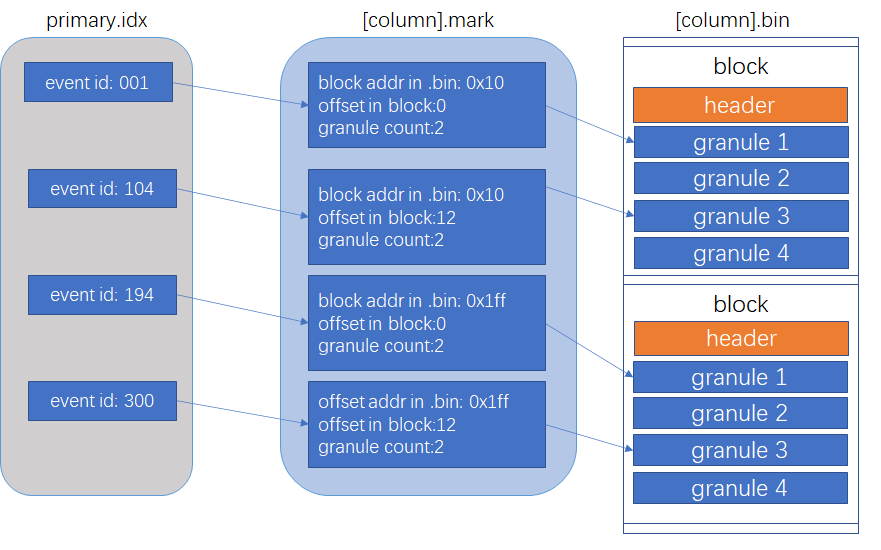
A mark points to the first line of a granule (granule), containing two pieces of information: 1. The relative position of the block in the file; 2. The relative position in the uncompressed block.
A granule is a concept, which can be understood as a data granule. Each granule contains several rows of data for a column, and the quantity is generally determined by index_granularity.
[column].mrk
When reading a range of data is required, such as reading the data of a certain column with primary keys from 1000 to 2000, there is no need to read all the data with primary keys from 0 to 1000 and above 2000 into memory. The introduction of the .mrk file (mark file / marker file) is to solve this most basic problem.
The mark file maintains a mapping from a mark to a set of continuous granules (granule range), and a granule belongs to a block, with a block containing multiple granules. The stored information is as follows:
- offset_in_compressed_file: The offset of the corresponding block in the compressed .bin file. Since the actual .bin file contains compressed content, it can also be understood as the offset position of the block in the .bin file. This information can be used to quickly read the block’s content.
- offset_in_decompressed_block: The offset of the first granule in the decompressed block. After the block is read from the disk and decompressed into memory, it is necessary to locate the position of the granule, and this information is used to quickly locate the corresponding granule’s offset position in the block.
The following is the actual code of the corresponding implementation class. It saves two long values, one is the offset of the block, and the other is the offset within the block.
size_t offset_in_compressed_file;
size_t offset_in_decompressed_block;
The introduction of marks means that the index does not need to map to a specific row but needs to map to a certain range on a mark, reducing the index file, reducing the index items, reducing IO (recall the index of a general database B+ tree), and speeding up the search speed. Clickhouse’s index points to a mark, and a mark represents n rows of data for a column, not a single data, so Clickhouse’s index is also called a sparse index.
Reference code: src\Compression\CompressedReadBufferFromFile.cpp, src\Formats\MarkInCompressedFile.h
primary.idx
In Clickhouse, the primary key is the column or the first part of the multi-column order by, and the data is stored according to the order by, so the primary key in Clickhouse’s storage is always ordered. The primary.idx serves as the primary index, maintaining a mapping from the primary key to the mark. The primary index will not store all the primary keys, nor will it maintain all the mappings from the primary key to the mark. However, because the stored primary keys are ordered, binary search can be used to quickly locate which mark the required primary key is on.
For example, in the primary index below, if you want to find the data for the primary key = 5 of a certain column, you can use binary search. We know that the primary keys of 7 and above and 1 and below are definitely not the range we are looking for, so the data we are looking for will only be on the mark corresponding to the primary key = 4 (since it is generally sorted from small to large, the primary = 4 actually corresponds to the smallest primary key on the mark).
skp_idx_[column].idx & skp_idx_[column].mrk
Skipping index is a type of sparse index. The purpose is to skip useless areas to narrow down the query range and improve query efficiency. Skipping index is divided into several categories:
-
minmax Range query, including equal query to exclude impossible data ranges.
-
set(max rows) Used for equal queries.
-
ngram bloom filter
A bloom filter that tokenizes according to the ngram algorithm, quickly confirming that the data you are looking for is not on a certain or several continuous granules.
-
token bloom filter
Similar to the ngram bloom filter, but tokenizes according to punctuation.
Skipping index points from the index key to the mark, such as {min, max} -> mark; {bloom filter} -> mark.
columns.txt
Records the information of columns, including name and type.
count.txt
Records the total number of rows of data in the current partition Data part.
default_compression_codec.txt
Saves the compression algorithm of the block.
Partition.dat
Saves a value, which is the number of the partition, starting from 0.
Partition Merging
Each Insert operation will produce a new partition directory, so Clickhouse periodically or forcibly triggers partition merging operations. Partition merging is to merge multiple partition directories with the same Partition ID into one directory, because the original data belongs to a partition.
Forced merging of partitions is done through the optimize command, for example:
OPTIMIZE TABLE <table name> [final]
By default, it merges a part at a time to avoid blocking other Clickhouse operations. If you want to merge all at once, add final.
It is clear that the merged partition contains all the data of the original partition, so the name of the new merged partition directory is:
PartitionID_{minimum of all MinBlockNum}_{maximum of all MaxBlockNum}_{incremented Level}
Level is self-increasing, and it increases by one each time it is merged.
After each mutation, a new part is produced, and its level value is the highest, while the original parts will be gradually removed in the background.